
在线服务的目标应该是提供与业务需求匹配的可用服务。此流程的关键部分应该涉及组织中的不同团队,例如,从业务开发团队到工程团队。
要验证一个服务如何符合这些目标,可以用这些目标可衡量的“成就”来定义“阈值”,例如,“服务必须在 99.9% 的时间内可用”,这应该与用户的期望和业务连续性相匹配。
SLA, SLO, SLI
已经有很多关于这些话题的文章,如果你不熟悉这些术语,我强烈建议你先阅读谷歌关于 SLO(服务级别目标) 的 SRE 书籍中的文章。
总而言之:
-
SLA:服务水平协议
-
你承诺向用户提供的服务,如果你无法满足,可能会受到惩罚。
-
例如:“99.5%”的可用性。
-
关键词:合同
-
-
SLO:服务水平目标
-
你在内部设置的目标,驱动你的测量阈值 (例如,仪表板和警报)。通常,它应该比 SLA 更严格。
-
示例:“99.9%”可用性 (所谓的“三个 9”)。
-
关键字:阈值
-
-
SLI:服务水平指标
-
你实际测量的是什么,以确定你的 SLO 是否在满足目标 / 偏离目标。
-
示例:错误率、延迟。
-
关键词:指标。
-
SLO 关注时间
99% 的可用性意味着什么?它不是 1% 的错误率 (失败的 http 响应的百分比),而是在一个预定义的时间段内可用服务的时间百分比。
在上面的仪表板中,服务在 1 小时内的错误率超过 0.1% (y 轴为 0.001)(错误峰值顶部的红色小水平段),从而在 7 天内提供 99.4% 的可用性:
这一结果中的一个关键因素是你选择度量可用性的时间跨度 (在上面的示例中为 7 天)。较短的周期通常用作工程团队 (例如 SRE 和 SWE) 的检查点,以跟踪服务的运行情况,而较长的周期通常用于组织 / 更广泛的团队的评审目的。
例如,如果你设置了 99.9% 的 SLO,那么服务可以停机的总时间如下:
-
30 天:43 分钟 (3/4 小时)
-
90 天:129 分钟 (~2 小时)
另一个无关紧要的“数字事实”是,给 SLO 多加一个 9 都会产生明显的指数级影响。以下是 1 年的时间跨度的时间组成部分:
-
2 个 9: 99%: 5250min (87hrs 或 3.64 天)
-
3 个 9: 99.9%: 525min (8.7hrs)
-
4 个 9: 99.99%: 52.5min
-
5 个 9:99.999%:5min< - 经验法则:5 个 9 -> 5 分钟 (每年)
输入错误预算
在服务可以停机的允许时间内,上面的数字可能被认为是错误预算,你可以从以下事件中消耗这些错误预算:


 在研究、应用机器学习算法的经历中,相信大伙儿经常遇到数据集太大、内存不够用的情况。 这引出一系列问题: 怎么加载十几、几十 GB 的数据文件? 运行数据集的时候算法崩溃了,...
在研究、应用机器学习算法的经历中,相信大伙儿经常遇到数据集太大、内存不够用的情况。 这引出一系列问题: 怎么加载十几、几十 GB 的数据文件? 运行数据集的时候算法崩溃了,...  在线服务的目标应该是提供与业务需求匹配的可用服务。此流程的关键部分应该涉及组织中的不同团队,例如,从业务开发团队到工程团队。 要验证一个服务如何符合这些目标,可以用...
在线服务的目标应该是提供与业务需求匹配的可用服务。此流程的关键部分应该涉及组织中的不同团队,例如,从业务开发团队到工程团队。 要验证一个服务如何符合这些目标,可以用...  一、数据库命令规范 所有数据库对象名称必须使用小写字母并用下划线分割; 所有数据库对象名称禁止使用 mysql 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来...
一、数据库命令规范 所有数据库对象名称必须使用小写字母并用下划线分割; 所有数据库对象名称禁止使用 mysql 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来...  mysql主从实现 Mycat不负责任何的数据同步问题,mysql的主从复制还得从mysql层面来实现;如果没有实现mysql的主从复制,后文就都成 如果想学习Java工程化、高性能及分布式、深入浅出。微...
mysql主从实现 Mycat不负责任何的数据同步问题,mysql的主从复制还得从mysql层面来实现;如果没有实现mysql的主从复制,后文就都成 如果想学习Java工程化、高性能及分布式、深入浅出。微...  VBA中的变量区分对象变量与非对象变量,采用不同的赋值方式。同时,对于对象变量,又区分内置对象与非内置对象,在语法上有所区别。对于非内置对象的引用,可以使用前期绑定或...
VBA中的变量区分对象变量与非对象变量,采用不同的赋值方式。同时,对于对象变量,又区分内置对象与非内置对象,在语法上有所区别。对于非内置对象的引用,可以使用前期绑定或...  MySQL 是世界上最流行的开源数据库系统,MariaDB(一个 MySQL 分支)是世界上增长最快的开源数据库系统。在安装 MySQL 服务器之后,在默认配置下是不安全的,确保数据库安全通常是通用数...
MySQL 是世界上最流行的开源数据库系统,MariaDB(一个 MySQL 分支)是世界上增长最快的开源数据库系统。在安装 MySQL 服务器之后,在默认配置下是不安全的,确保数据库安全通常是通用数... 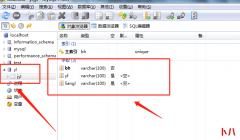 数据已经存放到列表当中了,接下来要将数据放到数据库中 那么我们应该创建对应的数据表 创建对应的类及其属性,放到entity包下 准备连接数据库的工具类 编写连接数据库的代码 创建...
数据已经存放到列表当中了,接下来要将数据放到数据库中 那么我们应该创建对应的数据表 创建对应的类及其属性,放到entity包下 准备连接数据库的工具类 编写连接数据库的代码 创建...  MySQL 里有两个日志,即:重做日志(redo log)和归档日志(binlog)。 其中,binlog 可以给备库使用,也可以保存起来用于恢复数据库历史数据。它是实现在 server 层的,所有引擎可以共用...
MySQL 里有两个日志,即:重做日志(redo log)和归档日志(binlog)。 其中,binlog 可以给备库使用,也可以保存起来用于恢复数据库历史数据。它是实现在 server 层的,所有引擎可以共用...  我知道MySQL看我不顺眼,不就是他的好基友Tomcat不怎么搭理他了吗? 这能怪我? 谁让他那么慢? 张大胖把我Redis安排到这个系统中来,那就是为了提升系统的响应速度,我把数据都暂时...
我知道MySQL看我不顺眼,不就是他的好基友Tomcat不怎么搭理他了吗? 这能怪我? 谁让他那么慢? 张大胖把我Redis安排到这个系统中来,那就是为了提升系统的响应速度,我把数据都暂时...  局域网共享设置mysql安装教程...
局域网共享设置mysql安装教程... 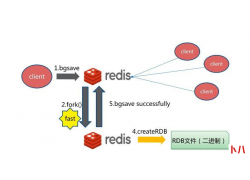 1:读取数据的时候先从redis里面查,若没有,再去数据库查,同时写到redis里面,并且要设置失效时间。 2:存数据的...
1:读取数据的时候先从redis里面查,若没有,再去数据库查,同时写到redis里面,并且要设置失效时间。 2:存数据的...  作者 |guangsu. 来源 |https://blog.csdn.net/qq_30549099/article/details/107395521 通常能听到的...
作者 |guangsu. 来源 |https://blog.csdn.net/qq_30549099/article/details/107395521 通常能听到的... 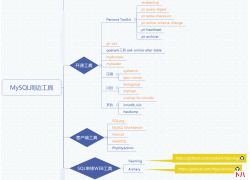 目前已收集的并在实际环境中使用过的 开源工具如下: 可以说掌握了这些工具...
目前已收集的并在实际环境中使用过的 开源工具如下: 可以说掌握了这些工具...  创建数据库 create database db1; 删除数据库 drop database db1; 创建数据表 create table...
创建数据库 create database db1; 删除数据库 drop database db1; 创建数据表 create table...  来源:谈数据,作者:石秀峰 全文共 3678 个字,建议阅读 6 分钟 数据中台为什...
来源:谈数据,作者:石秀峰 全文共 3678 个字,建议阅读 6 分钟 数据中台为什...  线上库有6个表存在重复数据,其中2个表比较大,一个96万+、一个30万+,因为之...
线上库有6个表存在重复数据,其中2个表比较大,一个96万+、一个30万+,因为之... 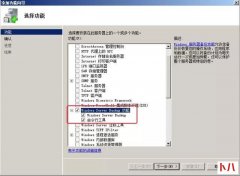 EFS 加密操作步骤如下: 1. 右键点击文件或文件夹,选择属性,点击高级属性,勾选加密内容以便保护数据。 2. 加密完成后,Windows 7 以上操作系统会在右下角弹出气泡,提示备份密钥,...
EFS 加密操作步骤如下: 1. 右键点击文件或文件夹,选择属性,点击高级属性,勾选加密内容以便保护数据。 2. 加密完成后,Windows 7 以上操作系统会在右下角弹出气泡,提示备份密钥,... 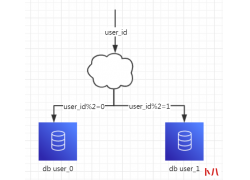 关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力...
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力...  在MySQL中进行数据备份的方法有两种: 1. mysqlhotcopy 这个命令会在拷贝文件之前会把表锁住,并把数据同步到数据文件中,以避免拷贝到不完整的数据文件,是最安全快捷的备份方法。...
在MySQL中进行数据备份的方法有两种: 1. mysqlhotcopy 这个命令会在拷贝文件之前会把表锁住,并把数据同步到数据文件中,以避免拷贝到不完整的数据文件,是最安全快捷的备份方法。...  最近有个上位机获取下位机上报数据的项目,由于上报频率比较频繁且数据量大,导致数据增长过快,磁盘占用多。...
最近有个上位机获取下位机上报数据的项目,由于上报频率比较频繁且数据量大,导致数据增长过快,磁盘占用多。... 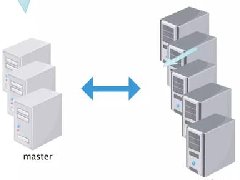 一、Kubernetes 是 Google 团队发起并维护的基于 Docker 的开源容器集群管理系统,它不仅支持常见的云平台,而且支持内部数据中心。 建于 Docker 之上的 Kubernetes 可以构建一个容器的调度服...
一、Kubernetes 是 Google 团队发起并维护的基于 Docker 的开源容器集群管理系统,它不仅支持常见的云平台,而且支持内部数据中心。 建于 Docker 之上的 Kubernetes 可以构建一个容器的调度服...  通过组合索引降低逻辑读,从而降低CPU资源的使用,从而解决DBTime值异常增长...
通过组合索引降低逻辑读,从而降低CPU资源的使用,从而解决DBTime值异常增长... 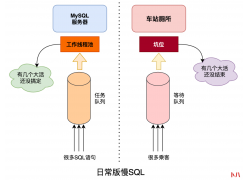 今天和大家聊一个常见的问题:慢SQL。通过本文你将了解到以下内容:慢SQL的危害SQL语句的执行过程存储引擎和索引...
今天和大家聊一个常见的问题:慢SQL。通过本文你将了解到以下内容:慢SQL的危害SQL语句的执行过程存储引擎和索引...  对于许多组织来说,将应用程序迁移到云端可以容忍短暂的停机时间,因为会得到明确的好处。采用云计算看起来就像一个明智周全的投资,通常很容易找出成本理由。然而,人们关于...
对于许多组织来说,将应用程序迁移到云端可以容忍短暂的停机时间,因为会得到明确的好处。采用云计算看起来就像一个明智周全的投资,通常很容易找出成本理由。然而,人们关于...  说起MySQL的查询优化,相信大家收藏了一堆奇技淫巧:不能使用SELECT *、不使用...
说起MySQL的查询优化,相信大家收藏了一堆奇技淫巧:不能使用SELECT *、不使用...  索引优化规则 1、like语句的前导模糊查询不能使用索引。 select * from doc where...
索引优化规则 1、like语句的前导模糊查询不能使用索引。 select * from doc where...  来源: juejin.cn/post/6844903968259178504 主从复制解决的问题 数据分布:通过复制将...
来源: juejin.cn/post/6844903968259178504 主从复制解决的问题 数据分布:通过复制将... 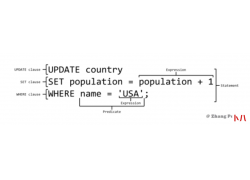 一、基本概念 数据库术语 数据库(database) - 保存有组织的数据的容器(通常...
一、基本概念 数据库术语 数据库(database) - 保存有组织的数据的容器(通常...  来源 | https://zhenbianshu.github.io/ Redis 作为一个非常成功的数据库,提供了非常丰...
来源 | https://zhenbianshu.github.io/ Redis 作为一个非常成功的数据库,提供了非常丰...