
有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个

代码所在
-
Git:https://github.com/asciimoo/searx
官方很贴心,很方便的是已经提供了docker 镜像,基本pull下来就可以很方便的使用了,执行命令
cid=$(sudo docker ps -a | grep searx | awk '{print $1}')
echo searx cid is $cid
if [ "$cid" != "" ];then
sudo docker stop $cid
sudo docker rm $cid
fi
sudo docker run -d --name searx -e IMAGE_PROXY=True -e BASE_URL=http://yourdomain.com -p 7777:8888 wonderfall/searx
然后就可以使用了,正常查看docker的状态,就可以正常的使用了
思考
怎么样,是不是很方便,我们先看看源码是怎么样实现的
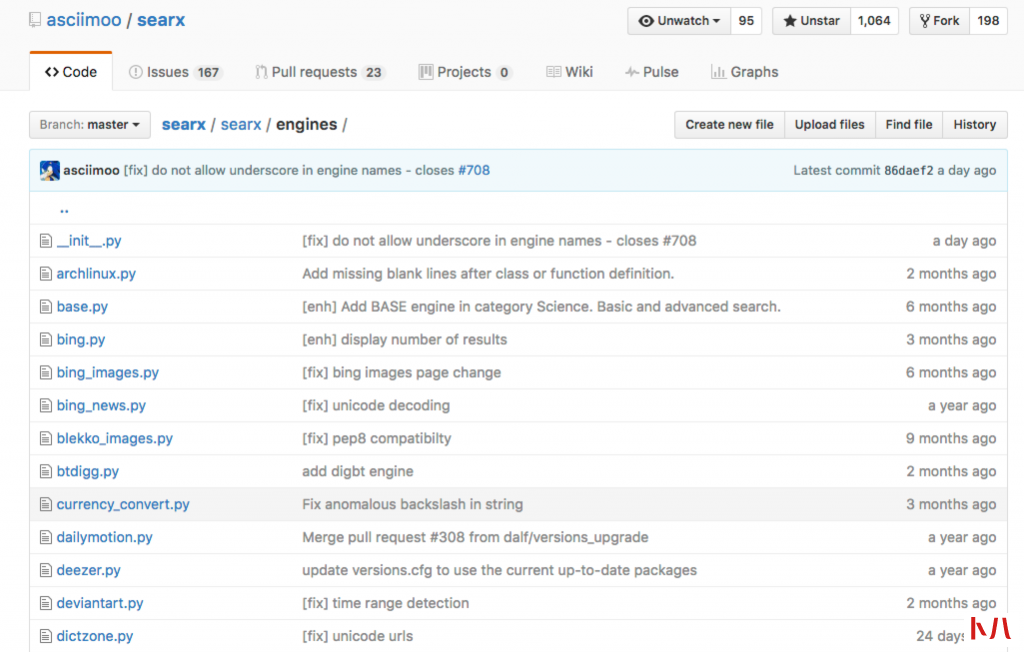
我们打开里面的代码,其实本质就是将request之后的结果做一个大的聚合,至于数据来源,我们可以是来于DB,或者文件,我们可以看一下他的核心代码
from urllib import urlencode
from json import loads
from collections import Iterable
search_url = None
url_query = None
content_query = None
title_query = None
suggestion_query = ''
results_query = ''
# parameters for engines with paging support
#
# number of results on each page
# (only needed if the site requires not a page number, but an offset)
page_size = 1
# number of the first page (usually or 1)
first_page_num = 1
def iterate(iterable):
if type(iterable) == dict:
it = iterable.iteritems()
else:
it = enumerate(iterable)
for index, value in it:
yield str(index), value
def is_iterable(obj):
if type(obj) == str:
return False
if type(obj) == unicode:
return False
return isinstance(obj, Iterable)
def parse(query):
q = []
for part in query.split('/'):
if part == '':
continue
else:
q.append(part)
return q
def do_query(data, q):
ret = []
if not q:
return ret
qkey = q[]
for key, value in iterate(data):
if len(q) == 1:
if key == qkey:
ret.append(value)
elif is_iterable(value):
ret.extend(do_query(value, q))
else:
if not is_iterable(value):
continue
if key == qkey:
ret.extend(do_query(value, q[1:]))
else:
ret.extend(do_query(value, q))
return ret
def query(data, query_string):
q = parse(query_string)
return do_query(data, q)
def request(query, params):
query = urlencode({'q': query})[2:]
fp = {'query': query}
if paging and search_url.find('{pageno}') >= :
fp['pageno'] = (params['pageno'] - 1) * page_size + first_page_num
params['url'] = search_url.format(**fp)
params['query'] = query
return params
def response(resp):
results = []
json = loads(resp.text)
if results_query:
for result in query(json, results_query)[]:
url = query(result, url_query)[]
title = query(result, title_query)[]
content = query(result, content_query)[]
results.append({'url': url, 'title': title, 'content': content})
else:
for url, title, content in zip(
query(json, url_query),
query(json, title_query),
query(json, content_query)
):
results.append({'url': url, 'title': title, 'content': content})
if not suggestion_query:
return results
for suggestion in query(json, suggestion_query):
results.append({'suggestion': suggestion})
return results
结果
每个response的时候我们都要以轻松的定制返回的数据(可以是网络,可以是数据库,可以是文件),那我们进一步想一下,如果我们可以hack response 结果,那我们完全可以将自己爬来的数据做为返回结果。如果是1024之类的,完全可以打造自己的“爱好”小引擎,代码我就不贴了,大家可以自己动手自己玩玩。结合jieba分词,可以更好玩一点。


 本人已习惯使用Linux的命令,回过头来使用Windows原生Cmd感觉很不爽。也有很多...
本人已习惯使用Linux的命令,回过头来使用Windows原生Cmd感觉很不爽。也有很多...  pdf是一种便携式文档格式,由Adobe公司设计。因为不受平台限制,且方便保存和...
pdf是一种便携式文档格式,由Adobe公司设计。因为不受平台限制,且方便保存和...  在前几个月,Thinkphp连续爆发了多个严重漏洞。由于框架应用的广泛性,漏洞影响非常大。为了之后更好地防御和应对此框架漏洞,天融信阿尔法实验室对Thinkphp框架进行了详细地分析,...
在前几个月,Thinkphp连续爆发了多个严重漏洞。由于框架应用的广泛性,漏洞影响非常大。为了之后更好地防御和应对此框架漏洞,天融信阿尔法实验室对Thinkphp框架进行了详细地分析,...  UEFI Firmware Parser,即UEFI固件解析器,它是一个简单的脚本模块集合。它可以解析、提取并重建UEFI固件卷宗。其中包括针对BIOS、OptionROM、Intel ME和其他格式的解析模块。 工具安装 这个模...
UEFI Firmware Parser,即UEFI固件解析器,它是一个简单的脚本模块集合。它可以解析、提取并重建UEFI固件卷宗。其中包括针对BIOS、OptionROM、Intel ME和其他格式的解析模块。 工具安装 这个模...  一开始打开github,一看是.net代码,一脸懵。第二天起来于心不甘,就想试试能不能根据代码逻辑以及函数名称分析一波算法。于是做了一波曲折但有趣的研究。现在将工具分享出来,希...
一开始打开github,一看是.net代码,一脸懵。第二天起来于心不甘,就想试试能不能根据代码逻辑以及函数名称分析一波算法。于是做了一波曲折但有趣的研究。现在将工具分享出来,希...  hdwiki这套系统分为两部分通读,它的代码逻辑非常有趣。一部分为程序路由,...
hdwiki这套系统分为两部分通读,它的代码逻辑非常有趣。一部分为程序路由,...  在前面内容的基础上,我们在UserDao中编写一个方法 在UserMappper中编写 编写测试类,这个测试类的查询条件全部不为空 查看结果 我们设置部分条件是空的,例如用户角色为空 我们修改...
在前面内容的基础上,我们在UserDao中编写一个方法 在UserMappper中编写 编写测试类,这个测试类的查询条件全部不为空 查看结果 我们设置部分条件是空的,例如用户角色为空 我们修改...  Python的定位非常明确,它是一种简单易用但又专业严谨的语言。或者说叫胶水语言。普通人也很容易入门。Python可以把各个基本程序拼接在一起协同运作。任何一个人只要愿意学习,可...
Python的定位非常明确,它是一种简单易用但又专业严谨的语言。或者说叫胶水语言。普通人也很容易入门。Python可以把各个基本程序拼接在一起协同运作。任何一个人只要愿意学习,可...  一、PLC的定义与分类PLC是以微处理器为基础,综合了计算机技术、自动控制技术和通信技术,用面向控制过程面向用户的自然语言编程,适应工业环境,简单易懂、操作方便、可靠性高...
一、PLC的定义与分类PLC是以微处理器为基础,综合了计算机技术、自动控制技术和通信技术,用面向控制过程面向用户的自然语言编程,适应工业环境,简单易懂、操作方便、可靠性高...  今天在搭完一个新的虚拟机后,在使用sudo yum -y update 的情况下,出现了提示...
今天在搭完一个新的虚拟机后,在使用sudo yum -y update 的情况下,出现了提示...  想要了解Spring中的AOP,我们先了解下代理模式 在生活中,我们经常会遇到代理,比如中介、婚介、黄牛、代理办证等等,这些代理会比我更有效率或者更好的完成我们想做的事情,可无...
想要了解Spring中的AOP,我们先了解下代理模式 在生活中,我们经常会遇到代理,比如中介、婚介、黄牛、代理办证等等,这些代理会比我更有效率或者更好的完成我们想做的事情,可无...  承接上一个练习,我们看一个小内容:resultMap自动映射级别 在之前这个例子中,我们可以看到User类中的userPassword属性和Address类中的userId属性均未在resultMap中进行匹配 那么我们编写一个...
承接上一个练习,我们看一个小内容:resultMap自动映射级别 在之前这个例子中,我们可以看到User类中的userPassword属性和Address类中的userId属性均未在resultMap中进行匹配 那么我们编写一个...  各位在企业中做Web漏洞扫描或者 渗透 测试的朋友,可能会经常遇到需要对图...
各位在企业中做Web漏洞扫描或者 渗透 测试的朋友,可能会经常遇到需要对图... 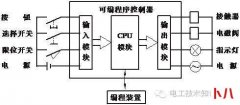 第一章可编程控制器简介 可编程序控制器,英文称Programmable Controller,简称PC。但由于PC容易和个人计算机(Personal Computer)混淆,故人们仍习惯地用PLC作为可编程序控制器的缩写。它是...
第一章可编程控制器简介 可编程序控制器,英文称Programmable Controller,简称PC。但由于PC容易和个人计算机(Personal Computer)混淆,故人们仍习惯地用PLC作为可编程序控制器的缩写。它是...  现在大部分搞前端的应该还是这样写 CSS 的: .mock { margin :auto; font-size : 16px ;...
现在大部分搞前端的应该还是这样写 CSS 的: .mock { margin :auto; font-size : 16px ;...  缓存设计可谓老生常谈了,早些时候都是采用 memcache ,现在大家更多倾向使用...
缓存设计可谓老生常谈了,早些时候都是采用 memcache ,现在大家更多倾向使用...  软件简单说明 DEDE标签精灵(Dede label elves) 是一款标签生成工具,可以快速...
软件简单说明 DEDE标签精灵(Dede label elves) 是一款标签生成工具,可以快速...  HTML一键打包EXE工具(HTML封装EXE,桌件)能把任意HTML项目(网址)一键打包为单个...
HTML一键打包EXE工具(HTML封装EXE,桌件)能把任意HTML项目(网址)一键打包为单个...  APP版本:V8.2.4.2961 工具:burpsuite,xposed,frida,儿童手表 0x1.接口分析 这里我...
APP版本:V8.2.4.2961 工具:burpsuite,xposed,frida,儿童手表 0x1.接口分析 这里我...  有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个...
有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个...  本文只针对比较流行的跳转型暗链作为研究对象,其他类型的暗链暂时不做讨...
本文只针对比较流行的跳转型暗链作为研究对象,其他类型的暗链暂时不做讨...  这一节介绍PLC的数据通信,数据通信在PLC的学习中是属于比较高级的应用,对于初学者来说觉得还是有一定的难度,许多朋友一接触通信就感觉头大,各种的云山雾罩,想要学习却又无...
这一节介绍PLC的数据通信,数据通信在PLC的学习中是属于比较高级的应用,对于初学者来说觉得还是有一定的难度,许多朋友一接触通信就感觉头大,各种的云山雾罩,想要学习却又无...  易语言是一个自主开发,适合国情,不同层次不同专业的人员易学易用的汉语...
易语言是一个自主开发,适合国情,不同层次不同专业的人员易学易用的汉语... 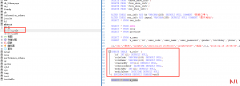 之前已经完成了MyBatis的增删改查,现在我们来处理一个问题,如果再JavaBean中有一个映射属性是个复杂类型比如在User用户表中,有一个Role角色属性。我们该如何处理,为了解决这个问...
之前已经完成了MyBatis的增删改查,现在我们来处理一个问题,如果再JavaBean中有一个映射属性是个复杂类型比如在User用户表中,有一个Role角色属性。我们该如何处理,为了解决这个问... 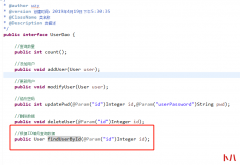 之前实现了用户的增删改,实现了一个简单的数据统计功能,但实际上查询的功能更为常见,我们看一下数据查询功能 首先我们根据ID编号查询一个数据,编辑对应的Dao和Mapper Mapper 编写对...
之前实现了用户的增删改,实现了一个简单的数据统计功能,但实际上查询的功能更为常见,我们看一下数据查询功能 首先我们根据ID编号查询一个数据,编辑对应的Dao和Mapper Mapper 编写对... 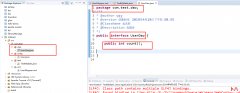 我们已经完成MyBatis的基础环境搭建,并完成了一种查询,这种方式是一种旧版本方式,还有一种官方推荐的方式,我们来看一下 我们创建一个接口 这个位置我们做了一个更改 在测试方...
我们已经完成MyBatis的基础环境搭建,并完成了一种查询,这种方式是一种旧版本方式,还有一种官方推荐的方式,我们来看一下 我们创建一个接口 这个位置我们做了一个更改 在测试方...  学习 Python 这么久了,今天我们来聊聊如何利用 Python 提升办公效率,在工作中...
学习 Python 这么久了,今天我们来聊聊如何利用 Python 提升办公效率,在工作中... 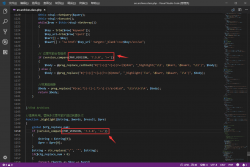 相信很多用DedeCMS的站友们都会为给文章做内链觉得繁琐,对于很多插件可能...
相信很多用DedeCMS的站友们都会为给文章做内链觉得繁琐,对于很多插件可能...  文 | 李晓飞 来源:Python 技术「ID: pythonall」 上一期,谈了如何用Python 打造运营...
文 | 李晓飞 来源:Python 技术「ID: pythonall」 上一期,谈了如何用Python 打造运营... 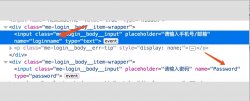 话说搞安全的大佬们都非常忙,自己在一步一步成长中无暇顾及其他琐碎的事...
话说搞安全的大佬们都非常忙,自己在一步一步成长中无暇顾及其他琐碎的事... 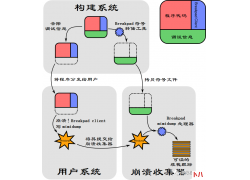 Breakpad 是 Google 用 C++ 编写的一个开源、跨平台的崩溃报告系统, 它支持 Wind...
Breakpad 是 Google 用 C++ 编写的一个开源、跨平台的崩溃报告系统, 它支持 Wind...  前言 周末花了2天时间学习了RabbitMQ,总结了最核心的知识点,带大家快速掌握...
前言 周末花了2天时间学习了RabbitMQ,总结了最核心的知识点,带大家快速掌握...  作者:网络小伙儿 1.存放用户账号的文件在哪里? /etc/passwd 2.如何删除一个非空...
作者:网络小伙儿 1.存放用户账号的文件在哪里? /etc/passwd 2.如何删除一个非空...  一、概念 幂等性, 通俗的说就是一个接口, 多次发起同一个请求, 必须保证操作...
一、概念 幂等性, 通俗的说就是一个接口, 多次发起同一个请求, 必须保证操作... 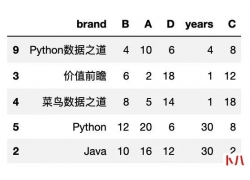 Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。 Pandas是一种高...
Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。 Pandas是一种高... 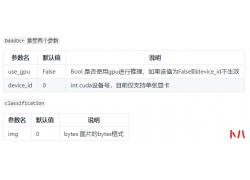 很久之前,分享过一次Python代码实现验证码识别的办法。 当时采用的是 pillo...
很久之前,分享过一次Python代码实现验证码识别的办法。 当时采用的是 pillo... 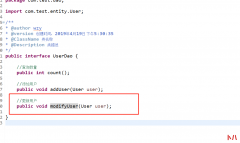 根据前面的内容我们可以完成插入,同样的方式我们可以完成修改更新 首先在UserDao添加modifyUser()方法 在UserMapper.xml文件中 编写测试方法 日志显示 原数据 新数据 如果修改个人密码的话...
根据前面的内容我们可以完成插入,同样的方式我们可以完成修改更新 首先在UserDao添加modifyUser()方法 在UserMapper.xml文件中 编写测试方法 日志显示 原数据 新数据 如果修改个人密码的话...  如果带 www 前缀的并且以 .com/.net/.org 结尾的,通常成功的机会要大很多。这个...
如果带 www 前缀的并且以 .com/.net/.org 结尾的,通常成功的机会要大很多。这个...  为什么很多人喜欢Python?对于初学者来说,这是一种简单易学的编程语言,另...
为什么很多人喜欢Python?对于初学者来说,这是一种简单易学的编程语言,另...  在《Effective C++》里 提到对内置 (C-like)类型在函数传参时 pass by value 比 pass by...
在《Effective C++》里 提到对内置 (C-like)类型在函数传参时 pass by value 比 pass by...  今天,我们就利用 Python 定制一款飞花令小程序: 给定一个关键字或者关键词...
今天,我们就利用 Python 定制一款飞花令小程序: 给定一个关键字或者关键词...  1、为什么选择Go语言 选择Go语言的原因可能会有很多,关于Go语言的特性、优势...
1、为什么选择Go语言 选择Go语言的原因可能会有很多,关于Go语言的特性、优势...  这篇文章介绍的内容是关于phpstudy虚拟域名配置,有着一定的参考价值,现在...
这篇文章介绍的内容是关于phpstudy虚拟域名配置,有着一定的参考价值,现在...  对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知...
对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知...  了解Redis Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,...
了解Redis Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,...