
各位在企业中做Web漏洞扫描或者渗透测试的朋友,可能会经常遇到需要对图形验证码进行程序识别的需求。很多时候验证码明明很简单(对于非互联网企业,或者企业内网中的应用来说特别如此),但因为没有趁手的识别库,也只能苦哈哈地进行人肉识别,或者无奈地放弃任务。在这里,我分享一下自己使用Python和开源的tesseract OCR引擎做验证码识别的经验,并提供相关的源代码和示例供大家借鉴。
一、关于图形验证码识别与tesseractOCR尽管多数图型验证码只有区区几个数字或字母,但你可能听说了,在进行机器识别的过程中,你要收集样本,对图片去噪、二值化、提取字符、计算特征,甚至还要祭出神经网络去训练数据进行机器学习……还没开干,退堂鼓早打响三遍了。其实我根本不想去钻研那么多高深的理论,只想要寥寥数行Python代码就搞定它,然后把主要精力投入到更重要的渗透测试中去。在这种情况下,tesseract就能帮上大忙了。
Tesseract的OCR引擎最早是HP实验室开发的,曾经是 OCR业内最准确的三款识别引擎之一。2005年该引擎交给了Google,作为开源项目发布在Google Project上了。Tesseract提供独立程序和API两种形式供用户使用。纯白色背景、字符规整无干扰像素的验证码图片可以直接调用tesseract程序来进行识别。如要更方便灵活地在自己的程序中进行识别,则可以使用tesseract的API。
二、Tesseract的编译和安装Tesseract的项目主页(https://github.com/tesseract-ocr/tesseract)上wiki中有详细的编译安装步骤,大家可以参考,本文中我们将以3.05.01版本为基础。我的系统环境是RHEL 7.4,64位版本。首先用yum安装各种依赖的图形库,然后用源码安装Leptonica(官方主页,版本需要1.74以上),编译安装很简单,解压后,以默认参数依次执行configure,make,make install命令即可。安装完之后需执行:
exportPKG_CONFIG_PATH=/usr/local/lib/pkgconfig不然在下一步tesseract的configure脚本会报找不到Leptonica。
将tesseract的源码解压后进入到源码主目录下依次执行:
./autogen.sh ./configure--with-extra-libraries=/usr/local/lib make make install即可成功安装。
根据项目wiki,Data Files节的指南下载相应的数据文件,因为我们只识别英文和数字验证码,所以下载3.04/3.05版本的英语文件eng.traineddata即可,下载后放到/usr/local/share/tessdata目录下。至此,tesseract就安装完毕了。
三、为Python封装tesseract APItesseract提供的是C++ API(接口界面是TessBaseAPI类),最核心的函数就是TessBaseAPI::TesseractRect这个函数。为了能在Python中方便地使用,我将其封装为Python模块了,详细代码放在github上:https://github.com/penoxcn/Decaptcha。该模块名为decaptcha,源文件包括以下四个文件:
setup.py、decaptcha.i、decaptcha.h和depcaptcha.cpp。
将以上文件放在同一个临时目录下,然后执行以下命令进行编译和安装:
python setup.py install安装时需要调用swig命令,所以系统需要先安装swig。
如果tesseract不是安装在默认的路径下,请参照setup.py代码自行修改相关的头文件和库文件的路径即可。
安装完之后进入Python交互环境试着import一下看是否正常:
from decaptcha import Decaptcha如果报错找不到libtesseract,那可能是tesseract的库目录(/usr/local/lib)没有在Python的库搜索目录中。这时候可以将tesseract的库目录添加到系统的/etc/ld.so.conf文件中(加了之后需要执行ldconfig命令以生效);或者每次import decaptcha模块之前,都先执行以下Python代码:
import sys sys.path.append("/usr/local/lib") 四、安装Python PIL库PIL的全称是Python Imaging Library,是一个强大而易用的图像库。在其主页()下载最新版(截止目前是1.1.7)源代码进行安装。安装之前确保系统已安装了png/jpeg/tiff等图像库。解压缩之后,在主目录下执行python setup.py install即可。
使用很简单,下面的代码片段从任意格式图片文件创建一个Image对象,进行格式转换,获得其大小和像素数组,只需几行代码:
from PIL import Image img = Image.open('test.png') # Your image here! img = img.convert("RGBA") pixdata = img.load() width,height = img.size print 'imgsize: %dx %d' % (width, height) print'pixel[2,4]:', pixdata[2, 4] #eg,(0xD3,0xD3,0xD3,0xFF) 五、实战验证码识别至此,进行图形验证码识别的依赖环境都已准备好,我们可以开干了。
识别的流程简单来说如下:
1. 用Image加载图像,转为RGBA格式,然后获取像素数据;
2. 将RGBA格式的像素数据转换为0和1的字节串(其实就是二值化处理);
3. 调用decaptcha模块进行图像识别,获得验证码字符串


 本人已习惯使用Linux的命令,回过头来使用Windows原生Cmd感觉很不爽。也有很多...
本人已习惯使用Linux的命令,回过头来使用Windows原生Cmd感觉很不爽。也有很多...  pdf是一种便携式文档格式,由Adobe公司设计。因为不受平台限制,且方便保存和...
pdf是一种便携式文档格式,由Adobe公司设计。因为不受平台限制,且方便保存和...  在前几个月,Thinkphp连续爆发了多个严重漏洞。由于框架应用的广泛性,漏洞影响非常大。为了之后更好地防御和应对此框架漏洞,天融信阿尔法实验室对Thinkphp框架进行了详细地分析,...
在前几个月,Thinkphp连续爆发了多个严重漏洞。由于框架应用的广泛性,漏洞影响非常大。为了之后更好地防御和应对此框架漏洞,天融信阿尔法实验室对Thinkphp框架进行了详细地分析,...  UEFI Firmware Parser,即UEFI固件解析器,它是一个简单的脚本模块集合。它可以解析、提取并重建UEFI固件卷宗。其中包括针对BIOS、OptionROM、Intel ME和其他格式的解析模块。 工具安装 这个模...
UEFI Firmware Parser,即UEFI固件解析器,它是一个简单的脚本模块集合。它可以解析、提取并重建UEFI固件卷宗。其中包括针对BIOS、OptionROM、Intel ME和其他格式的解析模块。 工具安装 这个模...  一开始打开github,一看是.net代码,一脸懵。第二天起来于心不甘,就想试试能不能根据代码逻辑以及函数名称分析一波算法。于是做了一波曲折但有趣的研究。现在将工具分享出来,希...
一开始打开github,一看是.net代码,一脸懵。第二天起来于心不甘,就想试试能不能根据代码逻辑以及函数名称分析一波算法。于是做了一波曲折但有趣的研究。现在将工具分享出来,希... 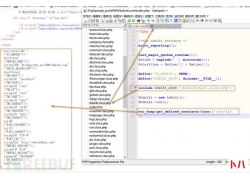 hdwiki这套系统分为两部分通读,它的代码逻辑非常有趣。一部分为程序路由,...
hdwiki这套系统分为两部分通读,它的代码逻辑非常有趣。一部分为程序路由,... 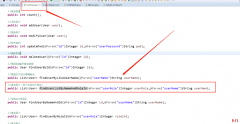 在前面内容的基础上,我们在UserDao中编写一个方法 在UserMappper中编写 编写测试类,这个测试类的查询条件全部不为空 查看结果 我们设置部分条件是空的,例如用户角色为空 我们修改...
在前面内容的基础上,我们在UserDao中编写一个方法 在UserMappper中编写 编写测试类,这个测试类的查询条件全部不为空 查看结果 我们设置部分条件是空的,例如用户角色为空 我们修改...  Python的定位非常明确,它是一种简单易用但又专业严谨的语言。或者说叫胶水语言。普通人也很容易入门。Python可以把各个基本程序拼接在一起协同运作。任何一个人只要愿意学习,可...
Python的定位非常明确,它是一种简单易用但又专业严谨的语言。或者说叫胶水语言。普通人也很容易入门。Python可以把各个基本程序拼接在一起协同运作。任何一个人只要愿意学习,可...  一、PLC的定义与分类PLC是以微处理器为基础,综合了计算机技术、自动控制技术和通信技术,用面向控制过程面向用户的自然语言编程,适应工业环境,简单易懂、操作方便、可靠性高...
一、PLC的定义与分类PLC是以微处理器为基础,综合了计算机技术、自动控制技术和通信技术,用面向控制过程面向用户的自然语言编程,适应工业环境,简单易懂、操作方便、可靠性高...  今天在搭完一个新的虚拟机后,在使用sudo yum -y update 的情况下,出现了提示...
今天在搭完一个新的虚拟机后,在使用sudo yum -y update 的情况下,出现了提示...  想要了解Spring中的AOP,我们先了解下代理模式 在生活中,我们经常会遇到代理,比如中介、婚介、黄牛、代理办证等等,这些代理会比我更有效率或者更好的完成我们想做的事情,可无...
想要了解Spring中的AOP,我们先了解下代理模式 在生活中,我们经常会遇到代理,比如中介、婚介、黄牛、代理办证等等,这些代理会比我更有效率或者更好的完成我们想做的事情,可无... 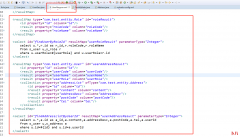 承接上一个练习,我们看一个小内容:resultMap自动映射级别 在之前这个例子中,我们可以看到User类中的userPassword属性和Address类中的userId属性均未在resultMap中进行匹配 那么我们编写一个...
承接上一个练习,我们看一个小内容:resultMap自动映射级别 在之前这个例子中,我们可以看到User类中的userPassword属性和Address类中的userId属性均未在resultMap中进行匹配 那么我们编写一个...  各位在企业中做Web漏洞扫描或者 渗透 测试的朋友,可能会经常遇到需要对图...
各位在企业中做Web漏洞扫描或者 渗透 测试的朋友,可能会经常遇到需要对图... 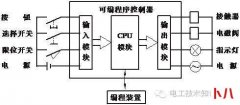 第一章可编程控制器简介 可编程序控制器,英文称Programmable Controller,简称PC。但由于PC容易和个人计算机(Personal Computer)混淆,故人们仍习惯地用PLC作为可编程序控制器的缩写。它是...
第一章可编程控制器简介 可编程序控制器,英文称Programmable Controller,简称PC。但由于PC容易和个人计算机(Personal Computer)混淆,故人们仍习惯地用PLC作为可编程序控制器的缩写。它是...  现在大部分搞前端的应该还是这样写 CSS 的: .mock { margin :auto; font-size : 16px ;...
现在大部分搞前端的应该还是这样写 CSS 的: .mock { margin :auto; font-size : 16px ;...  缓存设计可谓老生常谈了,早些时候都是采用 memcache ,现在大家更多倾向使用...
缓存设计可谓老生常谈了,早些时候都是采用 memcache ,现在大家更多倾向使用...  软件简单说明 DEDE标签精灵(Dede label elves) 是一款标签生成工具,可以快速...
软件简单说明 DEDE标签精灵(Dede label elves) 是一款标签生成工具,可以快速...  HTML一键打包EXE工具(HTML封装EXE,桌件)能把任意HTML项目(网址)一键打包为单个...
HTML一键打包EXE工具(HTML封装EXE,桌件)能把任意HTML项目(网址)一键打包为单个...  APP版本:V8.2.4.2961 工具:burpsuite,xposed,frida,儿童手表 0x1.接口分析 这里我...
APP版本:V8.2.4.2961 工具:burpsuite,xposed,frida,儿童手表 0x1.接口分析 这里我...  有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个...
有一个群友在群里问个如何快速搭建一个搜索引擎,在搜索之后我看到了这个...  本文只针对比较流行的跳转型暗链作为研究对象,其他类型的暗链暂时不做讨...
本文只针对比较流行的跳转型暗链作为研究对象,其他类型的暗链暂时不做讨...  这一节介绍PLC的数据通信,数据通信在PLC的学习中是属于比较高级的应用,对于初学者来说觉得还是有一定的难度,许多朋友一接触通信就感觉头大,各种的云山雾罩,想要学习却又无...
这一节介绍PLC的数据通信,数据通信在PLC的学习中是属于比较高级的应用,对于初学者来说觉得还是有一定的难度,许多朋友一接触通信就感觉头大,各种的云山雾罩,想要学习却又无...  易语言是一个自主开发,适合国情,不同层次不同专业的人员易学易用的汉语...
易语言是一个自主开发,适合国情,不同层次不同专业的人员易学易用的汉语... 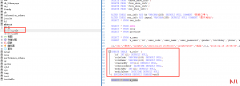 之前已经完成了MyBatis的增删改查,现在我们来处理一个问题,如果再JavaBean中有一个映射属性是个复杂类型比如在User用户表中,有一个Role角色属性。我们该如何处理,为了解决这个问...
之前已经完成了MyBatis的增删改查,现在我们来处理一个问题,如果再JavaBean中有一个映射属性是个复杂类型比如在User用户表中,有一个Role角色属性。我们该如何处理,为了解决这个问... 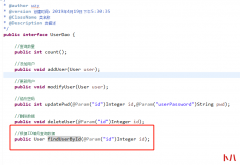 之前实现了用户的增删改,实现了一个简单的数据统计功能,但实际上查询的功能更为常见,我们看一下数据查询功能 首先我们根据ID编号查询一个数据,编辑对应的Dao和Mapper Mapper 编写对...
之前实现了用户的增删改,实现了一个简单的数据统计功能,但实际上查询的功能更为常见,我们看一下数据查询功能 首先我们根据ID编号查询一个数据,编辑对应的Dao和Mapper Mapper 编写对... 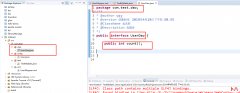 我们已经完成MyBatis的基础环境搭建,并完成了一种查询,这种方式是一种旧版本方式,还有一种官方推荐的方式,我们来看一下 我们创建一个接口 这个位置我们做了一个更改 在测试方...
我们已经完成MyBatis的基础环境搭建,并完成了一种查询,这种方式是一种旧版本方式,还有一种官方推荐的方式,我们来看一下 我们创建一个接口 这个位置我们做了一个更改 在测试方...  学习 Python 这么久了,今天我们来聊聊如何利用 Python 提升办公效率,在工作中...
学习 Python 这么久了,今天我们来聊聊如何利用 Python 提升办公效率,在工作中...  相信很多用DedeCMS的站友们都会为给文章做内链觉得繁琐,对于很多插件可能...
相信很多用DedeCMS的站友们都会为给文章做内链觉得繁琐,对于很多插件可能...  文 | 李晓飞 来源:Python 技术「ID: pythonall」 上一期,谈了如何用Python 打造运营...
文 | 李晓飞 来源:Python 技术「ID: pythonall」 上一期,谈了如何用Python 打造运营...  话说搞安全的大佬们都非常忙,自己在一步一步成长中无暇顾及其他琐碎的事...
话说搞安全的大佬们都非常忙,自己在一步一步成长中无暇顾及其他琐碎的事... 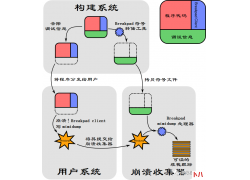 Breakpad 是 Google 用 C++ 编写的一个开源、跨平台的崩溃报告系统, 它支持 Wind...
Breakpad 是 Google 用 C++ 编写的一个开源、跨平台的崩溃报告系统, 它支持 Wind...  前言 周末花了2天时间学习了RabbitMQ,总结了最核心的知识点,带大家快速掌握...
前言 周末花了2天时间学习了RabbitMQ,总结了最核心的知识点,带大家快速掌握...  作者:网络小伙儿 1.存放用户账号的文件在哪里? /etc/passwd 2.如何删除一个非空...
作者:网络小伙儿 1.存放用户账号的文件在哪里? /etc/passwd 2.如何删除一个非空...  一、概念 幂等性, 通俗的说就是一个接口, 多次发起同一个请求, 必须保证操作...
一、概念 幂等性, 通俗的说就是一个接口, 多次发起同一个请求, 必须保证操作... 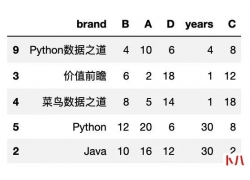 Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。 Pandas是一种高...
Pandas 可以说是 在Python数据科学领域应用最为广泛的工具之一。 Pandas是一种高... 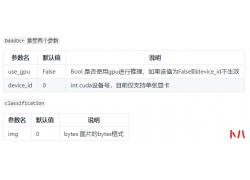 很久之前,分享过一次Python代码实现验证码识别的办法。 当时采用的是 pillo...
很久之前,分享过一次Python代码实现验证码识别的办法。 当时采用的是 pillo... 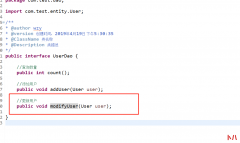 根据前面的内容我们可以完成插入,同样的方式我们可以完成修改更新 首先在UserDao添加modifyUser()方法 在UserMapper.xml文件中 编写测试方法 日志显示 原数据 新数据 如果修改个人密码的话...
根据前面的内容我们可以完成插入,同样的方式我们可以完成修改更新 首先在UserDao添加modifyUser()方法 在UserMapper.xml文件中 编写测试方法 日志显示 原数据 新数据 如果修改个人密码的话...  如果带 www 前缀的并且以 .com/.net/.org 结尾的,通常成功的机会要大很多。这个...
如果带 www 前缀的并且以 .com/.net/.org 结尾的,通常成功的机会要大很多。这个...  为什么很多人喜欢Python?对于初学者来说,这是一种简单易学的编程语言,另...
为什么很多人喜欢Python?对于初学者来说,这是一种简单易学的编程语言,另...  在《Effective C++》里 提到对内置 (C-like)类型在函数传参时 pass by value 比 pass by...
在《Effective C++》里 提到对内置 (C-like)类型在函数传参时 pass by value 比 pass by...  今天,我们就利用 Python 定制一款飞花令小程序: 给定一个关键字或者关键词...
今天,我们就利用 Python 定制一款飞花令小程序: 给定一个关键字或者关键词...  1、为什么选择Go语言 选择Go语言的原因可能会有很多,关于Go语言的特性、优势...
1、为什么选择Go语言 选择Go语言的原因可能会有很多,关于Go语言的特性、优势...  这篇文章介绍的内容是关于phpstudy虚拟域名配置,有着一定的参考价值,现在...
这篇文章介绍的内容是关于phpstudy虚拟域名配置,有着一定的参考价值,现在...  对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知...
对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知...  了解Redis Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,...
了解Redis Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,...