
通过组合索引降低逻辑读,从而降低CPU资源的使用,从而解决DBTime值异常增长。
观察DBTime告警曲线异常增长,从而生成了ASH报告,通过报告知道是CPU资源占用DBTime。从top SQL 看其中几条SQL都是全表扫描
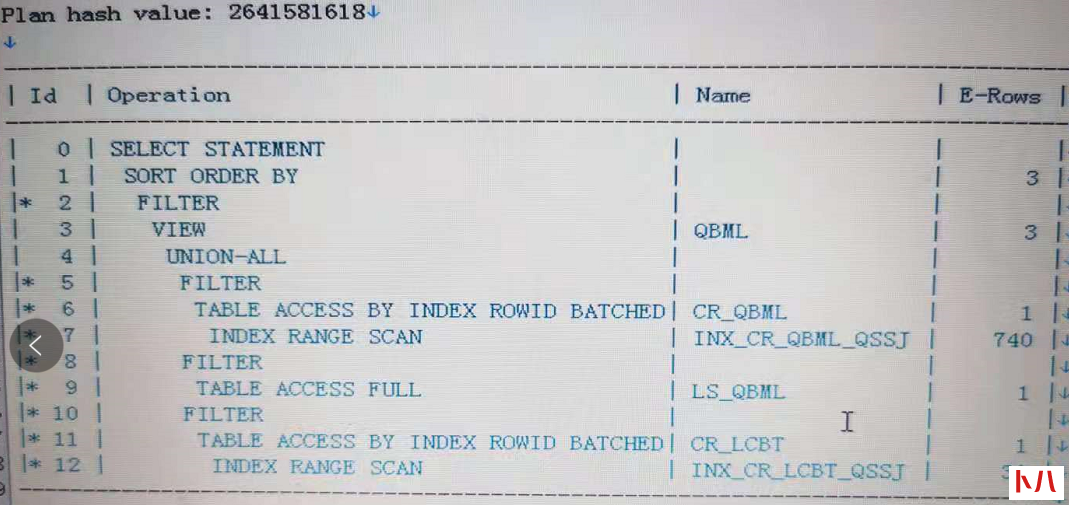
下面是一个SQL的执行计划,我们分析表,表上的字段以及字段数据分布等信息,通过创建一个组合索引消除全表扫描,使得逻辑读降低到之前的大概1/40
从后续观察看DBTime基本保持在1000左右,而之前最高冲到3700多。
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 31apzx76zt983, child number 0
-------------------------------------
select
PK,QBID,KHBZ,JC,SJ,SJM,SJBDH,ZMLM,TM,ZCC,LCCC,
SFCC,DZH,DZM,FZH,FZM,DDKYD,DDKYDMC,GD, to_char(DFRQ,'yyyy-mm-dd
hh24:mi:ss') DFRQ, JYZH,CS,ZZ,HC,YY,FYY,JZX,PBS,ZBR,JCR,ZTBZ,
CLBZ,JQBID,TRAINID,to_char(FSSJ,'yyyy-MM-dd hh24:mi:ss') FSSJ,
to_char(JSSJ,'yyyy-mm-dd hh24:mi:ss') JSSJ, to_char(QSSJ,'yyyy-mm-dd
hh24:mi:ss') QSSJ, KKH,CDZT,YWBZ,BWM,JYDDT,YSPK
from xxxx
where qssj between to_date(:1 ,'yyyy-mm-dd hh24:mi:ss') and to_date(:2
,'yyyy-mm-dd hh24:mi:ss') and jc = :3 and sjm = :4 order by qssj
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE(:2,'yyyy-mm-dd
hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
5 - filter(TO_DATE(:2,'yyyy-mm-dd
hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
6 - filter(("SJM"=:4 AND "JC"=:3 AND "ROUTENAME"<>'模拟发送' AND
"GD"<>'单机'))
7 - access("QSSJ">=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss') AND
"QSSJ"<=TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss'))
8 - filter(TO_DATE(:2,'yyyy-mm-dd
hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
9 - filter(("SJM"=:4 AND "JC"=:3 AND "GD"<>'单机' AND
"QSSJ">=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss') AND
"QSSJ"<=TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss') AND "ROUTENAME"<>'模拟发送'))
10 - filter(TO_DATE(:2,'yyyy-mm-dd
hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
11 - filter(("SJM"=:4 AND "JC"=:3 AND "GD"<>'单机' AND
"ROUTENAME"<>'模拟发送'))
12 - access("QSSJ">=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss') AND
"QSSJ"<=TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss'))
我们从执行计划分析可以知道 对象xxxx肯定不是一张表,因为在执行计划中我们看到三张表,从而可以推断他应该是
用户定义的视图。而这个视图包含对三张表的查询并做union all操作。
而第九步骤执行了全表扫描,再看Predicate Information部分
9 - filter(("SJM"=:4 AND "JC"=:3 AND "GD"<>'单机' AND
"QSSJ">=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss') AND
"QSSJ"<=TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss') AND "ROUTENAME"<>'模拟发送'))
这是我们创建索引的依据,此时的全表扫描是需要从每行记录中过滤数据,设计三个字段sjm,jc,qssj
我们通过查询字段的数据分布知道sjm和qssj适合创建索引,从过滤组合看,我们建议创建sjm和qssj的组合索引
等值查询字段在先。
COLUMN_NAME NDV NUL NUM_NULLS DATA_TYPE LOW_VAL_25 HIGH_VAL_25 LAST_ANALYZED
QSSJ 1406080 Y 0 DATE 78790415161A18 78790807150120 2021-08-09 22:35:50 HYBRID
SJM 61116 Y 0 VARCHAR2 31313030303032 39393939393939 2021-08-09 22:35:50
JC 27362 Y 3 VARCHAR2 2020444634442F34303832 BFE27373342F30393438 2021-08-09 22:35:50 HYBRID
下面创建组合索引,注意此时等值查询在前。
create index ZHGL.idx_LS_xxxx_SJM_QSSJ on ZHGL.LS_xxxx(SJM,QSSJ);
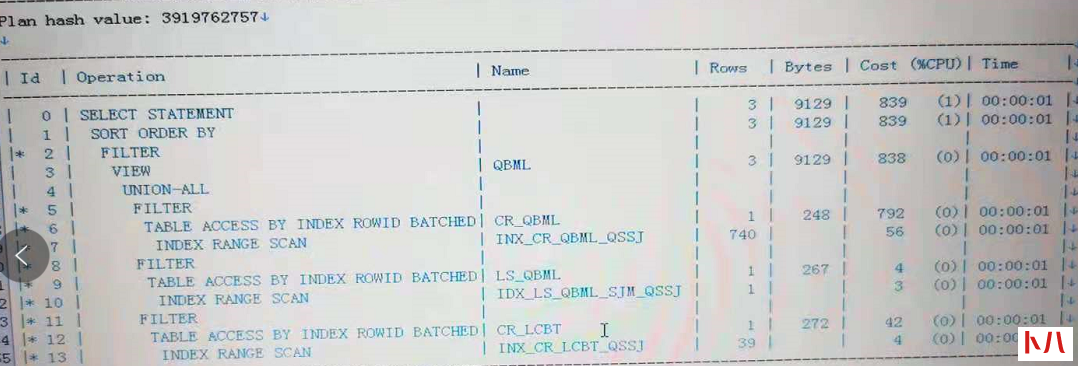
通过统计信息我们看执行计划是否变化。
explain plan for
select
PK,QBID,KHBZ,JC,SJ,SJM,SJBDH,ZMLM,TM,ZCC,LCCC,
SFCC,DZH,DZM,FZH,FZM,DDKYD,DDKYDMC,GD, to_char(DFRQ,'yyyy-mm-dd
hh24:mi:ss') DFRQ, JYZH,CS,ZZ,HC,YY,FYY,JZX,PBS,ZBR,JCR,ZTBZ,
CLBZ,JQBID,TRAINID,to_char(FSSJ,'yyyy-MM-dd hh24:mi:ss') FSSJ,
to_char(JSSJ,'yyyy-mm-dd hh24:mi:ss') JSSJ, to_char(QSSJ,'yyyy-mm-dd
hh24:mi:ss') QSSJ, KKH,CDZT,YWBZ,BWM,JYDDT,YSPK
from ZHGL.xxxx
where qssj between to_date(:1 ,'yyyy-mm-dd hh24:mi:ss') and to_date(:2
,'yyyy-mm-dd hh24:mi:ss') and jc = :3 and sjm = :4 order by qssj;
select * from table (dbms_xplan.display());
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
5 - filter(TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
6 - filter("SJM"=:4 AND "JC"=:3 AND "ROUTENAME"<>'模拟发送' AND "GD"<>'单机')
7 - access("QSSJ">=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss') AND "QSSJ"<=TO_DATE(:2,'yyyy-mm-dd
hh24:mi:ss'))
8 - filter(TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
9 - filter("JC"=:3 AND "GD"<>'单机' AND "ROUTENAME"<>'模拟发送')
10 - access("SJM"=:4 AND "QSSJ">=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss') AND
"QSSJ"<=TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss'))
11 - filter(TO_DATE(:2,'yyyy-mm-dd hh24:mi:ss')>=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss'))
12 - filter("SJM"=:4 AND "JC"=:3 AND "GD"<>'单机' AND "ROUTENAME"<>'模拟发送')
13 - access("QSSJ">=TO_DATE(:1,'yyyy-mm-dd hh24:mi:ss') AND "QSSJ"<=TO_DATE(:2,'yyyy-mm-dd
hh24:mi:ss'))
37 rows selected.
显然执行计划已经变化,第九步LS_xxxx表的数据通过索引找数据了,后续我们通过持续观察每个小时该SQL平均逻辑读
可以看到自从10点创建所有后,逻辑读明显下降,比例差不多是原先的1/40.
创建索引后的逻辑读统计
BTIME PLAN_HASH_VALUE EXECS AVG_ROWS AVG_ELAS AVG_CPUS AVG_LIOS AVG_PIOS
---------- --------------- ---------- ---------- ---------- ---------- ---------- ----------
0812 17:00 2641581618 250 .54 .962335636 .95882328 249025.044 0
0812 20:00 2641581618 356 .853932584 .956745787 .950190767 245281.051 .699438202
0813 07:00 2641581618 3641 .759956056 .955151072 .95122947 245954.167 .321889591
0813 08:00 2641581618 7161 .715402877 .970107745 .965671832 246854.346 .017595308 <<<之前逻辑读是246854.
0813 09:00 2641581618 12011 .710432104 1.0879792 1.07740201 0 .167013571
0813 10:00 3919762757 9776 .659472177 .016625501 .016200727 5433.31403 .154869067 <<<逻辑读降到5433
0813 11:00 3919762757 5816 .641678129 .017110643 .016668694 5775.44395 .116746905
0813 12:00 3919762757 2325 .660215054 .026489935 .025953871 9602.3428 .091612903
0813 13:00 3919762757 7032 .770193402 .020521865 .020023768 7513.56755 .108361775
结论: DBTime中CPU资源占比较高要看top SQL ,从而定位原因,一般是高逻辑读造成,优化的措施就是较少逻辑读,通过索引,缩表
或者业务执行层面减少逻辑读。


 在研究、应用机器学习算法的经历中,相信大伙儿经常遇到数据集太大、内存不够用的情况。 这引出一系列问题: 怎么加载十几、几十 GB 的数据文件? 运行数据集的时候算法崩溃了,...
在研究、应用机器学习算法的经历中,相信大伙儿经常遇到数据集太大、内存不够用的情况。 这引出一系列问题: 怎么加载十几、几十 GB 的数据文件? 运行数据集的时候算法崩溃了,...  在线服务的目标应该是提供与业务需求匹配的可用服务。此流程的关键部分应该涉及组织中的不同团队,例如,从业务开发团队到工程团队。 要验证一个服务如何符合这些目标,可以用...
在线服务的目标应该是提供与业务需求匹配的可用服务。此流程的关键部分应该涉及组织中的不同团队,例如,从业务开发团队到工程团队。 要验证一个服务如何符合这些目标,可以用...  一、数据库命令规范 所有数据库对象名称必须使用小写字母并用下划线分割; 所有数据库对象名称禁止使用 mysql 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来...
一、数据库命令规范 所有数据库对象名称必须使用小写字母并用下划线分割; 所有数据库对象名称禁止使用 mysql 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来...  mysql主从实现 Mycat不负责任何的数据同步问题,mysql的主从复制还得从mysql层面来实现;如果没有实现mysql的主从复制,后文就都成 如果想学习Java工程化、高性能及分布式、深入浅出。微...
mysql主从实现 Mycat不负责任何的数据同步问题,mysql的主从复制还得从mysql层面来实现;如果没有实现mysql的主从复制,后文就都成 如果想学习Java工程化、高性能及分布式、深入浅出。微...  VBA中的变量区分对象变量与非对象变量,采用不同的赋值方式。同时,对于对象变量,又区分内置对象与非内置对象,在语法上有所区别。对于非内置对象的引用,可以使用前期绑定或...
VBA中的变量区分对象变量与非对象变量,采用不同的赋值方式。同时,对于对象变量,又区分内置对象与非内置对象,在语法上有所区别。对于非内置对象的引用,可以使用前期绑定或...  MySQL 是世界上最流行的开源数据库系统,MariaDB(一个 MySQL 分支)是世界上增长最快的开源数据库系统。在安装 MySQL 服务器之后,在默认配置下是不安全的,确保数据库安全通常是通用数...
MySQL 是世界上最流行的开源数据库系统,MariaDB(一个 MySQL 分支)是世界上增长最快的开源数据库系统。在安装 MySQL 服务器之后,在默认配置下是不安全的,确保数据库安全通常是通用数...  数据已经存放到列表当中了,接下来要将数据放到数据库中 那么我们应该创建对应的数据表 创建对应的类及其属性,放到entity包下 准备连接数据库的工具类 编写连接数据库的代码 创建...
数据已经存放到列表当中了,接下来要将数据放到数据库中 那么我们应该创建对应的数据表 创建对应的类及其属性,放到entity包下 准备连接数据库的工具类 编写连接数据库的代码 创建...  MySQL 里有两个日志,即:重做日志(redo log)和归档日志(binlog)。 其中,binlog 可以给备库使用,也可以保存起来用于恢复数据库历史数据。它是实现在 server 层的,所有引擎可以共用...
MySQL 里有两个日志,即:重做日志(redo log)和归档日志(binlog)。 其中,binlog 可以给备库使用,也可以保存起来用于恢复数据库历史数据。它是实现在 server 层的,所有引擎可以共用...  我知道MySQL看我不顺眼,不就是他的好基友Tomcat不怎么搭理他了吗? 这能怪我? 谁让他那么慢? 张大胖把我Redis安排到这个系统中来,那就是为了提升系统的响应速度,我把数据都暂时...
我知道MySQL看我不顺眼,不就是他的好基友Tomcat不怎么搭理他了吗? 这能怪我? 谁让他那么慢? 张大胖把我Redis安排到这个系统中来,那就是为了提升系统的响应速度,我把数据都暂时...  局域网共享设置mysql安装教程...
局域网共享设置mysql安装教程... 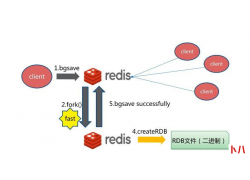 1:读取数据的时候先从redis里面查,若没有,再去数据库查,同时写到redis里面,并且要设置失效时间。 2:存数据的...
1:读取数据的时候先从redis里面查,若没有,再去数据库查,同时写到redis里面,并且要设置失效时间。 2:存数据的...  作者 |guangsu. 来源 |https://blog.csdn.net/qq_30549099/article/details/107395521 通常能听到的...
作者 |guangsu. 来源 |https://blog.csdn.net/qq_30549099/article/details/107395521 通常能听到的... 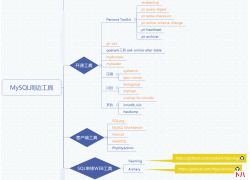 目前已收集的并在实际环境中使用过的 开源工具如下: 可以说掌握了这些工具...
目前已收集的并在实际环境中使用过的 开源工具如下: 可以说掌握了这些工具...  创建数据库 create database db1; 删除数据库 drop database db1; 创建数据表 create table...
创建数据库 create database db1; 删除数据库 drop database db1; 创建数据表 create table...  来源:谈数据,作者:石秀峰 全文共 3678 个字,建议阅读 6 分钟 数据中台为什...
来源:谈数据,作者:石秀峰 全文共 3678 个字,建议阅读 6 分钟 数据中台为什...  线上库有6个表存在重复数据,其中2个表比较大,一个96万+、一个30万+,因为之...
线上库有6个表存在重复数据,其中2个表比较大,一个96万+、一个30万+,因为之... 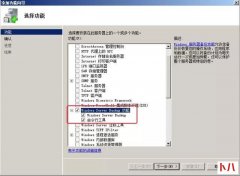 EFS 加密操作步骤如下: 1. 右键点击文件或文件夹,选择属性,点击高级属性,勾选加密内容以便保护数据。 2. 加密完成后,Windows 7 以上操作系统会在右下角弹出气泡,提示备份密钥,...
EFS 加密操作步骤如下: 1. 右键点击文件或文件夹,选择属性,点击高级属性,勾选加密内容以便保护数据。 2. 加密完成后,Windows 7 以上操作系统会在右下角弹出气泡,提示备份密钥,... 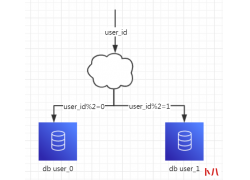 关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力...
关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力...  在MySQL中进行数据备份的方法有两种: 1. mysqlhotcopy 这个命令会在拷贝文件之前会把表锁住,并把数据同步到数据文件中,以避免拷贝到不完整的数据文件,是最安全快捷的备份方法。...
在MySQL中进行数据备份的方法有两种: 1. mysqlhotcopy 这个命令会在拷贝文件之前会把表锁住,并把数据同步到数据文件中,以避免拷贝到不完整的数据文件,是最安全快捷的备份方法。...  最近有个上位机获取下位机上报数据的项目,由于上报频率比较频繁且数据量大,导致数据增长过快,磁盘占用多。...
最近有个上位机获取下位机上报数据的项目,由于上报频率比较频繁且数据量大,导致数据增长过快,磁盘占用多。...  一、Kubernetes 是 Google 团队发起并维护的基于 Docker 的开源容器集群管理系统,它不仅支持常见的云平台,而且支持内部数据中心。 建于 Docker 之上的 Kubernetes 可以构建一个容器的调度服...
一、Kubernetes 是 Google 团队发起并维护的基于 Docker 的开源容器集群管理系统,它不仅支持常见的云平台,而且支持内部数据中心。 建于 Docker 之上的 Kubernetes 可以构建一个容器的调度服...  通过组合索引降低逻辑读,从而降低CPU资源的使用,从而解决DBTime值异常增长...
通过组合索引降低逻辑读,从而降低CPU资源的使用,从而解决DBTime值异常增长...  今天和大家聊一个常见的问题:慢SQL。通过本文你将了解到以下内容:慢SQL的危害SQL语句的执行过程存储引擎和索引...
今天和大家聊一个常见的问题:慢SQL。通过本文你将了解到以下内容:慢SQL的危害SQL语句的执行过程存储引擎和索引...  对于许多组织来说,将应用程序迁移到云端可以容忍短暂的停机时间,因为会得到明确的好处。采用云计算看起来就像一个明智周全的投资,通常很容易找出成本理由。然而,人们关于...
对于许多组织来说,将应用程序迁移到云端可以容忍短暂的停机时间,因为会得到明确的好处。采用云计算看起来就像一个明智周全的投资,通常很容易找出成本理由。然而,人们关于...  说起MySQL的查询优化,相信大家收藏了一堆奇技淫巧:不能使用SELECT *、不使用...
说起MySQL的查询优化,相信大家收藏了一堆奇技淫巧:不能使用SELECT *、不使用...  索引优化规则 1、like语句的前导模糊查询不能使用索引。 select * from doc where...
索引优化规则 1、like语句的前导模糊查询不能使用索引。 select * from doc where...  来源: juejin.cn/post/6844903968259178504 主从复制解决的问题 数据分布:通过复制将...
来源: juejin.cn/post/6844903968259178504 主从复制解决的问题 数据分布:通过复制将... 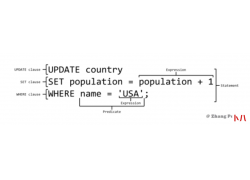 一、基本概念 数据库术语 数据库(database) - 保存有组织的数据的容器(通常...
一、基本概念 数据库术语 数据库(database) - 保存有组织的数据的容器(通常...  来源 | https://zhenbianshu.github.io/ Redis 作为一个非常成功的数据库,提供了非常丰...
来源 | https://zhenbianshu.github.io/ Redis 作为一个非常成功的数据库,提供了非常丰...